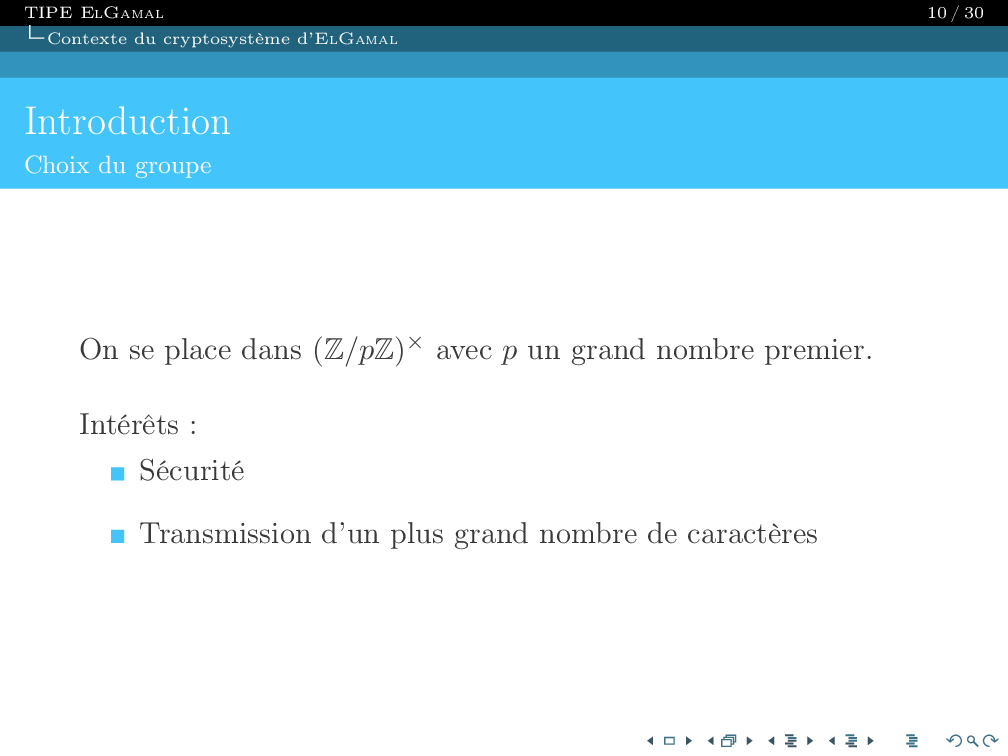
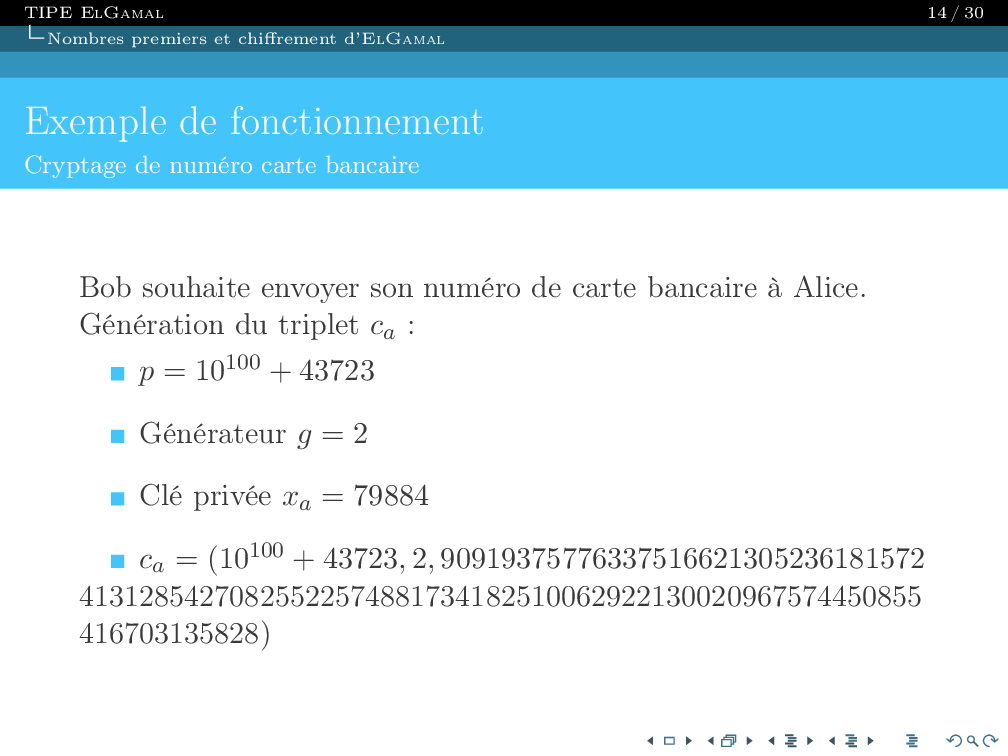
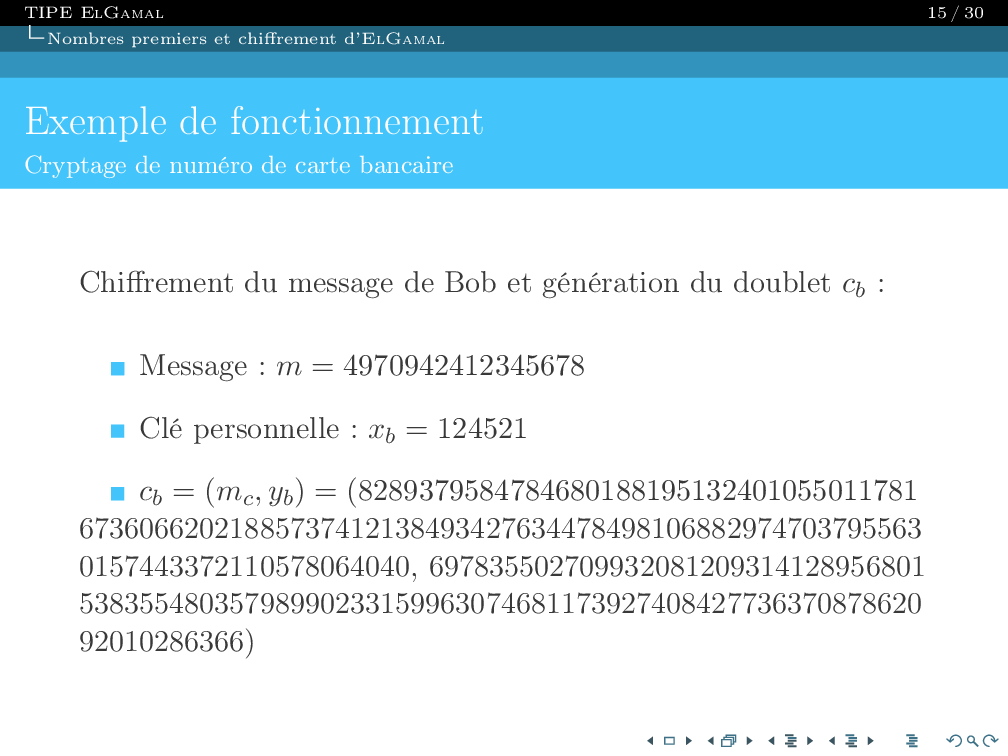
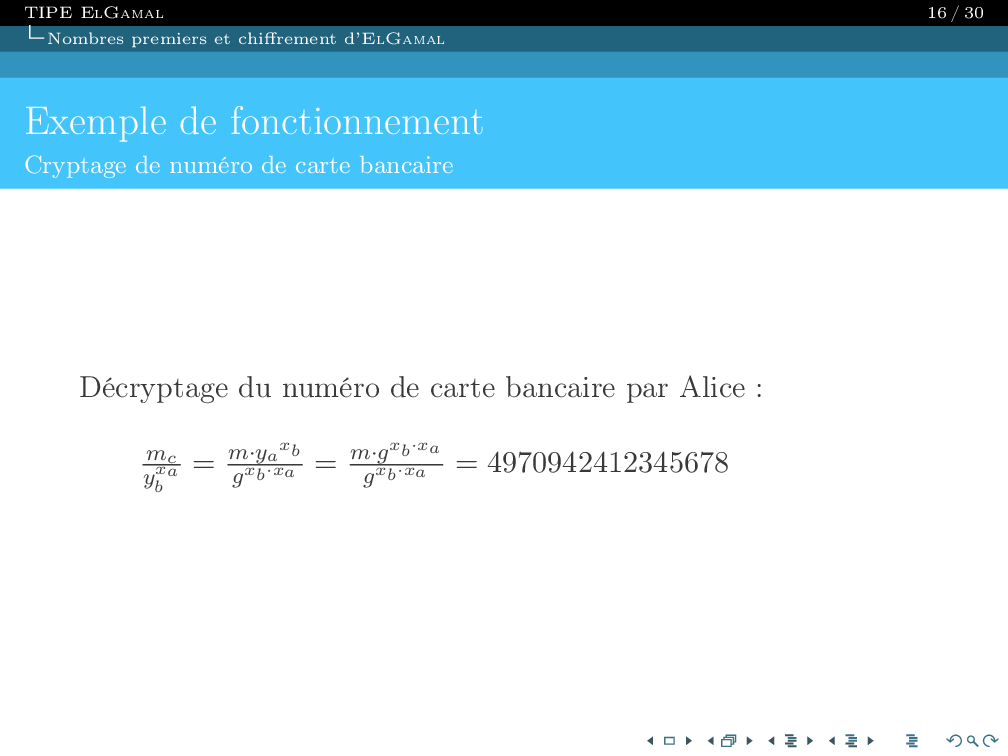
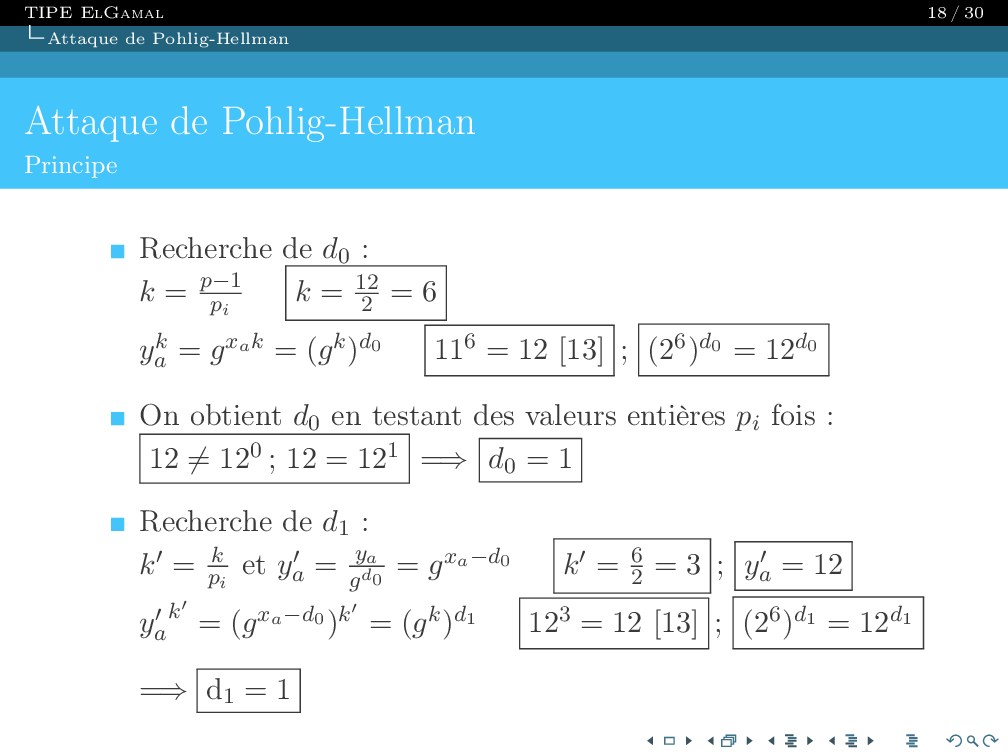
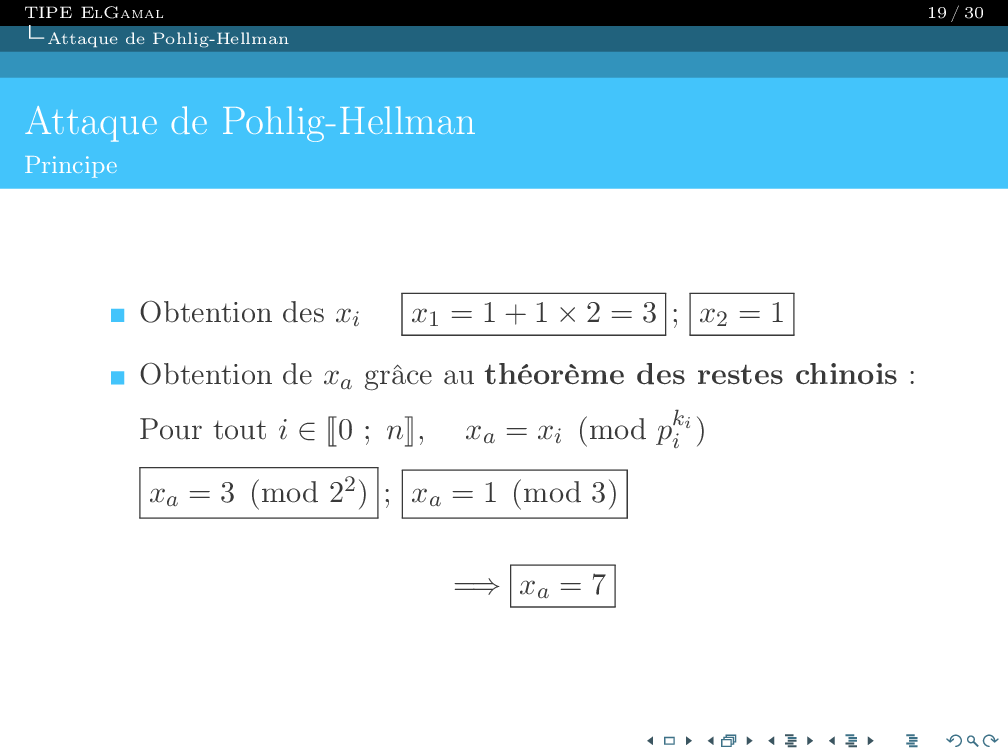
Je suis
Ingénieur en informatique.
Acutellement Ingénieur Logiciel chez Stryker.
Bienvenue sur mon portfolio. Vous pourrez y trouver mon expérience, mes compétences et mes projets.
Acutellement Ingénieur Logiciel chez Stryker.
Bienvenue sur mon portfolio. Vous pourrez y trouver mon expérience, mes compétences et mes projets.
Avril 2025 - Présent
Avril 2024 - Septembre 2024
Avril 2023 - Août 2023
2021 - 2024
2019 - 2021


Ce projet consiste en la création d'un jeu qui utilise l'apprentissage par renforcement. Nous avons donc créé un jeu dont l'entité apprend à jouer et à atteindre un objectif final par ses propres moyens. Le principe de notre jeu se rapproche plus ou moins de celui d'un labyrinthe.

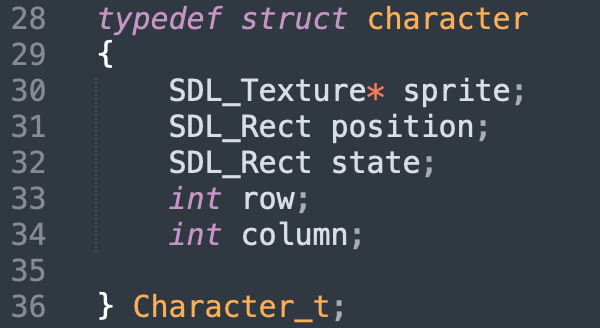
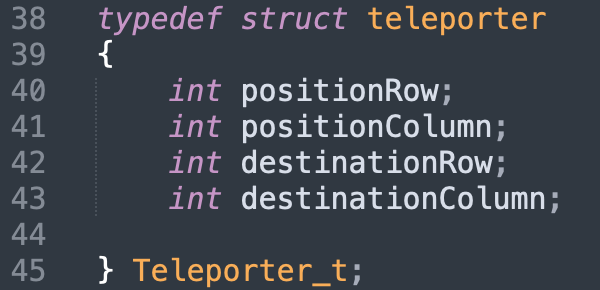
Comme nous l'avons expliqué précedemment, nous devons guider notre personnage de la case de départ vers la case d'arrivée en passant par des téléporteurs. Les téléporteurs sont liés deux à deux avec une couleur précise. Quand le personnage arrive sur un téléporteur, nous remarquons comme sur l'image qu'il fait une animation qui le mène vers le téléporteur correspondant.


Si notre personnage touche un trou, il est remis sur la position de départ. Nous utilisons l'animation de téléportation. En effet, la mort du personnage le téléporte directement sur la case de départ.

Lorsque le personnage atteint la case finale, il effectue un petit saut en tournant sur lui-même.


Nos perceptions sont en fonction des positions x et y du personnage dans la map. Nous avons 529 états qui dépendent de 4 directions.
L’IA suit l’algorithme de Q-Learning. Ainsi notre QTable est une matrice 529x4.
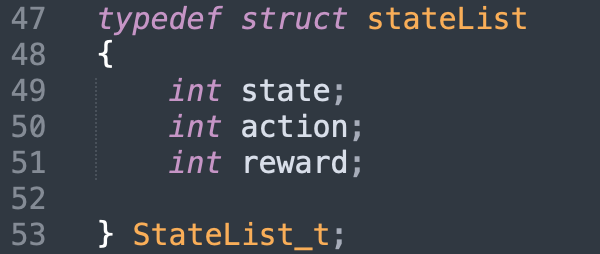
Notre système de reward est simple: 1 si le personnage a atteint le point d’arrivée, 0 sinon. Afin de déterminer les paramètres xi et gamma, nous avons réalisé différentes modélisations sur 500 000 générations.
Les meilleurs résultats sont pour xi = 0.8 et gamma = 0.93.
Le choix des actions est suivant l’algorithme E-greedy. Notre epsilon est une suite géométrique de paramètre 0.999.
Pour notre modélisation finale, cet epsilon décroit tous les 150 générations.
Une fois cette modélisation faite, on sauvegarde la QTable résultante et on la charge dans le programme global pour faire bouger notre personnage
avec l’expérience des générations précédentes.

Notre point d'arrivée correspond à l’état 265, les états 264 et 266 correspondent respectivement aux cases à gauche et droite de la case finale.
On remarque bien que les 1 dans les colonnes RIGHT et LEFT de chaque état.
Voici une démonstration du jeu en mode IA: